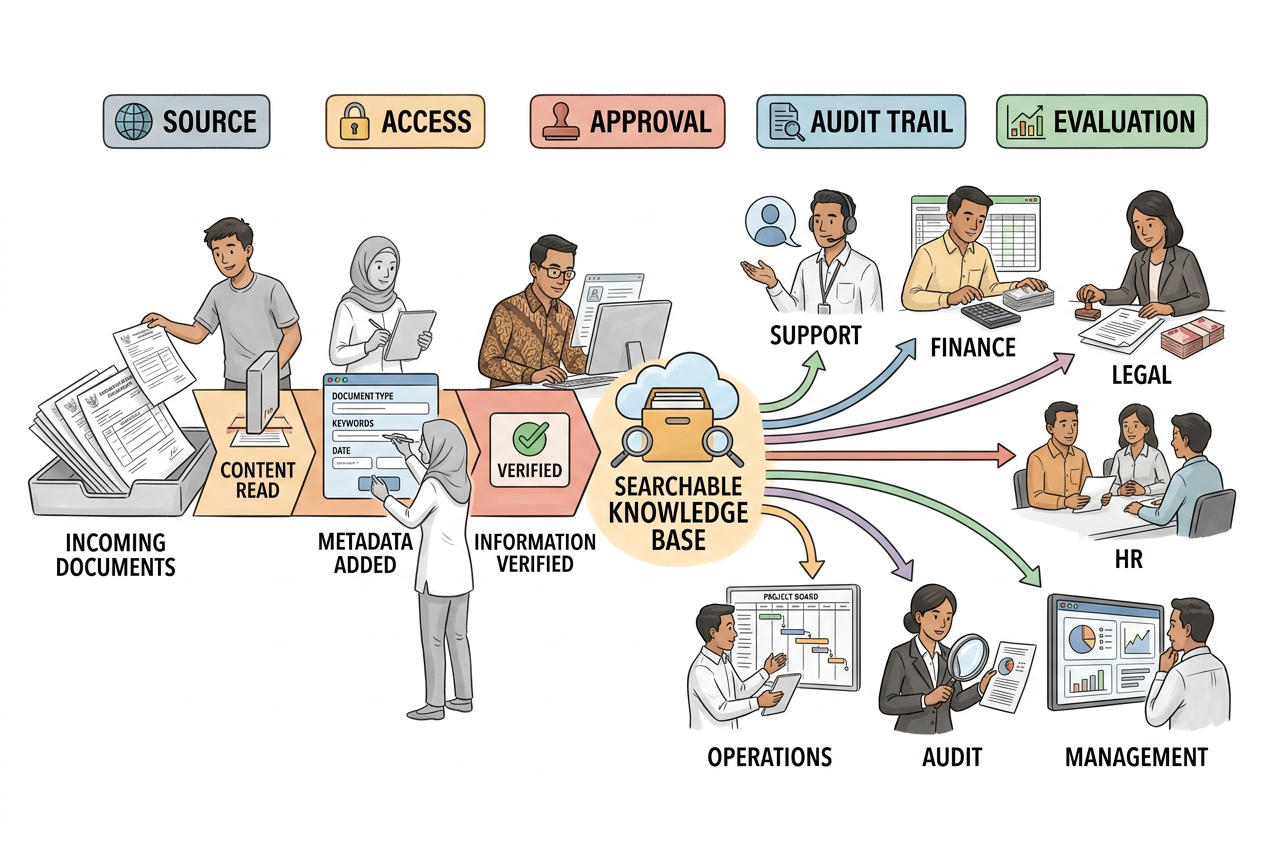
20.2 Jalur pemrosesan AI: Dari Dokumen ke Knowledge yang Bisa Dipakai
Bayangkan sebuah perusahaan logistik yang sudah beroperasi dua puluh tahun. Selama itu, mereka mengumpulkan ribuan dokumen: kontrak, addendum kontrak, surat keputusan, laporan risiko, memo internal, dan korespondensi dengan regulator. Semua dokumen tersimpan rapi di server file dan sistem manajemen dokumen. Tapi ketika seorang staf review risiko perlu mencari tahu apakah suatu kondisi permintaan layanan pernah ditangani sebelumnya, ia harus membuka folder demi folder, membaca PDF satu per satu, atau bertanya ke kolega yang mungkin ingat. Informasi ada, tetapi tidak bisa diakses dengan cepat.
Situasi ini bukan hanya terjadi di satu industri tertentu. Di perusahaan manapun yang sudah berumur, dokumen menumpuk, knowledge mengendap, dan waktu pencarian menjadi biaya tersembunyi yang besar. AI bisa membantu, tetapi tidak cukup dengan sekadar memberi satu prompt ke ChatGPT. Diperlukan sebuah jalur pemrosesan yang mengubah dokumen mentah menjadi knowledge yang bisa dipakai oleh banyak fungsi.
Jalur Pemrosesan ini dimulai dari pengumpulan dokumen. Dokumen dari berbagai sumber—email, PDF, scan, file Word, spreadsheet—dikumpulkan ke satu tempat. Ini bukan sekadar memindahkan file. Pengumpulan dokumen harus menangani format berbeda, mengenali struktur dokumen, dan mencatat metadata dasar seperti tanggal, pembuat, dan jenis dokumen. Tanpa pengumpulan dokumen yang rapi, langkah selanjutnya akan kacau.
Berikut diagram alur yang merangkum seluruh jalur pemrosesan tersebut:
Tahap kedua adalah pengambilan isi. Di sinilah AI mulai bekerja. Untuk dokumen cetak atau scan, AI mengambil teks dari gambar. Untuk PDF digital, teks langsung diekstrak. Tapi pengambilan isi tidak berhenti di teks mentah. AI perlu mengenali elemen penting: nomor kontrak, tanggal berlaku, nama pihak terkait, nilai transaksi, dan klausul khusus. Semakin baik pengambilan isi, semakin berguna data yang dihasilkan.
Berikut contoh kode Python yang menunjukkan ekstraksi teks dari PDF menggunakan PyMuPDF dan pembuatan embedding menggunakan sentence-transformers.
import fitz # PyMuPDF
from sentence_transformers import SentenceTransformer
def extract_text_from_pdf(pdf_path):
doc = fitz.open(pdf_path)
text = ""
for page in doc:
text += page.get_text()
doc.close()
return text
def create_embedding(text):
model = SentenceTransformer('all-MiniLM-L6-v2')
chunks = [text[i:i+500] for i in range(0, len(text), 500)]
embeddings = model.encode(chunks)
return embeddings
# Contoh penggunaan
teks_kontrak = extract_text_from_pdf('kontrak_2023.pdf')
vektor = create_embedding(teks_kontrak)
print(f"Jumlah chunk: {len(vektor)}, dimensi embedding: {len(vektor[0])}")
Setelah teks dan data terstruktur terkumpul, masuk ke pengelompokan. AI membaca dokumen dan menentukan kategori: ini dokumen kontrak, ini surat permintaan layanan, ini memo internal, ini laporan regulator. Pengelompokan memungkinkan sistem mengarahkan dokumen ke cara kerja yang tepat. Kontrak baru perlu disetujui review risiko. Permintaan layanan perlu masuk ke tim penyelesaian. Laporan regulator perlu diarsipkan dengan label khusus.
Tahap keempat adalah pengayaan konteks. Di sini AI menambahkan konteks yang tidak ada di dokumen asli. Misalnya, AI bisa menghubungkan nomor kontrak dengan data pelanggan dari sistem lain, menambahkan tag risiko berdasarkan analisis isi, atau mencocokkan klausul dengan regulasi terbaru. Pengayaan konteks membuat dokumen tidak lagi berdiri sendiri, tetapi terhubung dengan ekosistem data perusahaan.
Sekarang dokumen sudah siap untuk pencarian berbasis konteks. Ini adalah tahap di mana pengguna bisa bertanya dan mendapatkan jawaban. Ketika staf review risiko mengetik "apakah permintaan layanan dengan klausul force majeure pernah dibayarkan tahun lalu?", sistem tidak mencari kata persis. Ia memahami maksud pertanyaan, mengambil potongan dokumen yang relevan, dan menyusun jawaban. Pencarian berbasis konteks yang baik membutuhkan pemecahan dokumen yang tepat—dokumen dipecah menjadi bagian bermakna, bukan dipotong asal berdasarkan jumlah karakter.
Tapi pencarian berbasis konteks saja belum cukup. Seringkali dokumen yang ditemukan terlalu panjang untuk dibaca cepat. Di sinilah peringkasan berperan. AI merangkum isi dokumen, menyoroti poin penting, dan menyajikannya dalam format yang mudah dicerna. Peringkasan harus mempertahankan nuansa penting. Untuk dokumen hukum, satu kalimat bisa mengubah interpretasi. AI harus tahu mana yang esensial dan mana yang bisa diringkas.
Sebelum knowledge bisa dipakai secara resmi, perlu ada persetujuan. Tidak semua dokumen layak langsung menjadi referensi perusahaan. Sebuah memo internal mungkin perlu direview legal sebelum dijadikan acuan. Sebuah interpretasi kontrak mungkin perlu disetujui kepala review risiko. Persetujuan memastikan bahwa knowledge yang masuk ke sistem sudah melalui validasi manusia. AI bisa membantu mengusulkan, tetapi keputusan akhir tetap di tangan manusia yang bertanggung jawab.
Tahap terakhir adalah penerbitan. Knowledge yang sudah disetujui diterbitkan ke pusat pengetahuan, portal internal, atau sistem tiket. Sekarang knowledge bisa dipakai oleh seluruh organisasi: agen support menjawab pertanyaan pelanggan, staf review risiko mengecek kebijakan, tim compliance mencari bukti kepatuhan. Dokumen yang tadinya terkubur di folder kini menjadi aset yang aktif digunakan.
Jalur Pemrosesan ini tidak harus sempurna dari awal. Banyak perusahaan memulainya dari satu fungsi dulu, misalnya support atau compliance. Setelah jalur pemrosesan terbukti berjalan, baru diperluas ke fungsi lain. Yang penting adalah memahami bahwa AI bukan sekadar alat tanya-jawab. Ia adalah infrastruktur yang mengubah dokumen mati menjadi knowledge hidup.
Setelah jalur pemrosesan terbentuk, tantangan berikutnya adalah bagaimana memastikan jawaban yang diberikan AI akurat dan bisa dilacak asalnya. Dari titik ini, pembahasan bergerak ke subbab selanjutnya: bagaimana jawaban yang bisa ditelusuri sumbernya bekerja dengan metadata, pemecahan dokumen, dan penelusuran sumber.